(2024-06-27) Patel Notes Symbolic Species By Terrence Deacon
Dwarkesh Patel Notes: Symbolic Species by Terrence Deacon. ..the two of us got a chance to go have lunch with the author, Terence Deacon, a couple weeks ago
They ()Noam Chomsky and his followers) assert that the source of prior support for language acquisition must originate from inside the brain, on the unstated assumption that there is no other possible source. But there is another alternative: that the extra support for language learning is vested neither in the brain of the child nor in the brains of parents or teachers, but outside brains, in language itself.
May explain why LLMs have been so productive - language has evolved specifically to nanny a growing mind!
Since languages have evolved to be easy for children to learn, they might be far easier to model than other aspects of the world. And judging LLMs based on how good they are at modeling language means we may be overestimating how good they are at understanding other aspects of the world which have not evolved specifically for simple minds to grok (children have constrained associative learning and short term memory).
Childhood amnesia (where you can’t remember early parts of your life) is the result of the learning process kids use, where they prune and infer a lot more, allowing them to see the forrest for the trees.
On the opposite end of the spectrum are LLMs, which can remember entire passages of Wikipedia text verbatim but will flounder when you give them a new tic tac toe puzzle.
It’s really fascinating that this memorization-generalization spectrum exists.
As in other distributed pattern-learning problems, the problem in symbol learning is to avoid getting attracted to learning potholes—tricked into focusing on the probabilities of individual sign-object associations and thereby missing the nonlocal marginal probabilities of symbol-symbol regularities. Learning even a simple symbol system demands an approach that postpones commitment to the most immediately obvious associations until after some of the less obvious distributed relationships are acquired.
Why does grokking happen? Why is there double descent in neural networks. Sometimes, a model first learns only a superficial representation which doesn’t generalize beyond the training distribution. Only after significantly more training (which should paradoxically cause even more overfitting) does it learn the more general representation: (see graph)
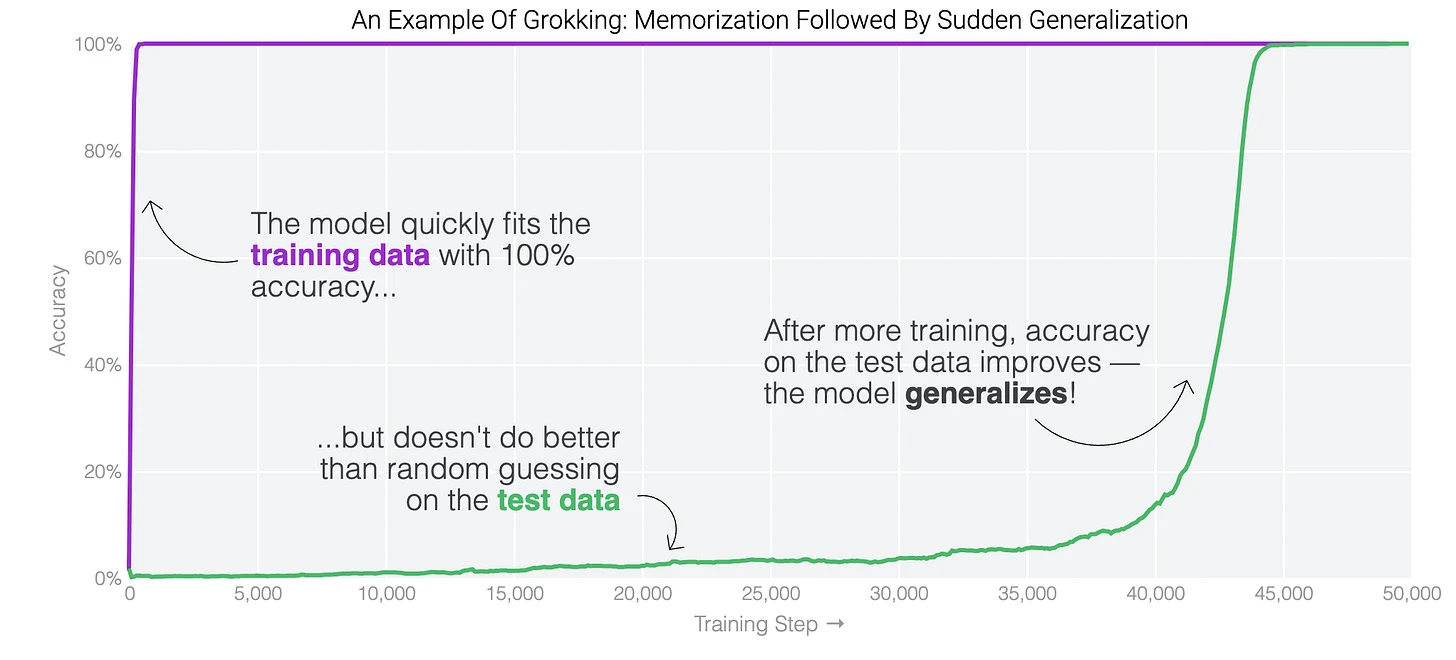
I think there’s a natural way to explain this phenomenon using Deacon’s ideas. Here’s a quote from his book:
The problem with symbol systems, then, is that there is both a lot of learning and unlearning that must take place before even a single symbolic relationship is available. Symbols cannot be acquired one at a time, the way other learned associations can, except after a reference symbol system is established. A logically complete system of relationships among the set of symbol tokens must be learned before the symbolic association between any one symbol token and an object can even be determined.
Even with a very small set of symbols the number of possible combinations is immense, and so sorting out which combinations work and which don’t requires sampling and remembering a large number of possibilities.
Here’s my attempt to translate in a way that makes sense of grokking. In order to understand some domain, you need to do a combinatorial search between all the underlying concepts to see how they are connected. But you can’t find this relation without first having all the concepts loaded into RAM. Then you can try out a bunch of different ways of connecting them, one of which happens to correspond to the compressed general representation of the whole idea.
It kinda sounds trivial when you put it like that - but the fact that a book in 1998 anticipated grokking is really interesting!
The process of discovering the new symbolic association is a restructuring event, in which the previously learned associations are suddenly seen in a new light and must be reorganized with respect to one another. This reorganization requires mental effort to suppress one set of associative responses in favor of another derived from them.
And with Deacon’s explanation, we can also describe how human cognitive abilities could arise out of simply scaling up chimp brains. Suppose you need have a brain at least as big as a humans to grok a language. As soon as you scale enough to hit that threshold, you’ve got this huge unhobbling of language.
Even surgical removal of most of the left hemisphere, including regions that would later have become classic language areas of the brain, if done early in childhood, may not preclude reaching nearly normal levels of adult language comprehension and production. In contrast, even very small localized lesions of the left hemisphere language regions in older children and adults can produce massive and irrecoverable deficits.
Seems like good evidence for the connectionist perspective, or Ilya’s take that “the model just want to learn.”
I didn’t realize how contingent speech as a method for communicating is. It just so happens that among the affordances pre-human apes had, it was easier to have them evolve more granular vocal cords to communicate symbolic relationships instead of faster hands to do sign language or something. Makes me more open to the possibility of galaxy brain level comms between AIs who can shoot representations in their latent space back and forth.
Edited: | Tweet this! | Search Twitter for discussion

 Made with flux.garden
Made with flux.garden